2.3 Edit menu
The Edit menu operations include operations to modify the
'edited gene list' that is set from a variety of Filters as well as
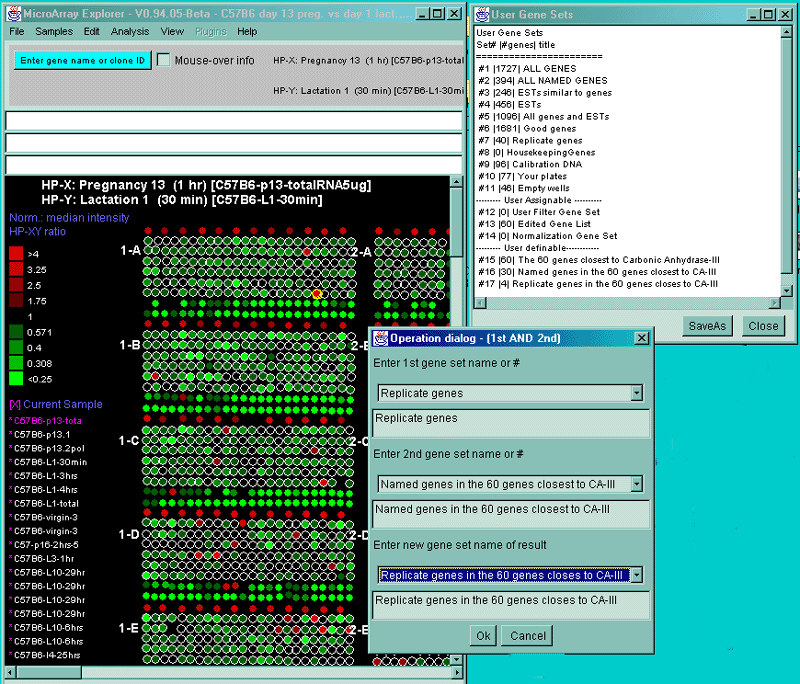
manually this menu. The user may perform set operations (union,
intersection, and difference) on named sets of gene and sets of sample
experiments (conditions). User preferences are also set in this menu.
Sets of genes or HP condition lists are very useful for tracking
complex data-mining sequences of analysis. For example, derived named
gene sets may be used in successive data filters and for reports. For
example, one could do the following experiment given four different
types of HPs for (e.g. virgin, pregnancy, lactation, and
involution)
The Edit menu contains the following main selections. All of these entities
and preferences are saved as part of the startup state when you
do a (File | Databases | SaveAs ... DB).
 - edit
the user defined 'Edited Gene List' or E.G.L.
- edit
the user defined 'Edited Gene List' or E.G.L.