**Icon Legend
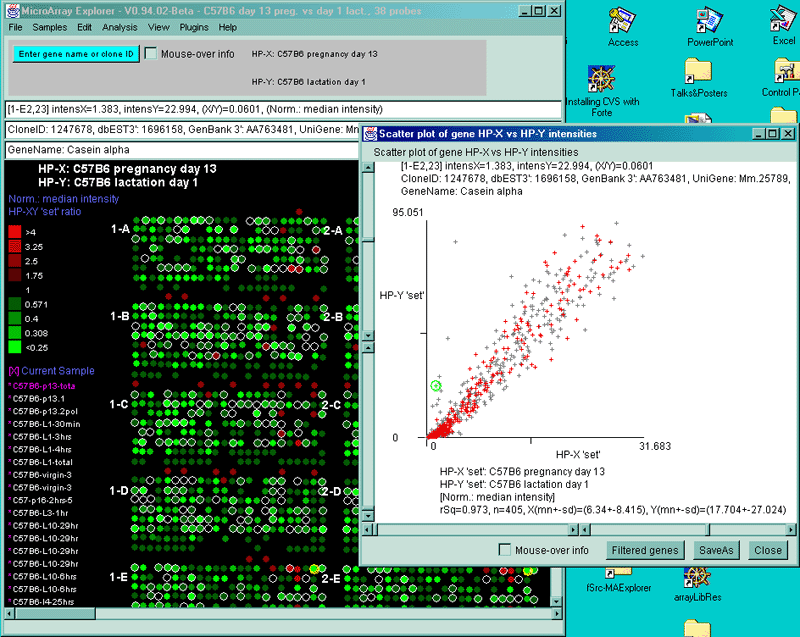
Data from a 38 sample subset of hybridized samples from the MGAP mouse microarray
database. This screen illustrates a synthetic pseudoarray image
showing the ratios of duplicated grids of genes comparing day 13
pregnancy in C57B6 mouse (sample HP-X 'set') with Lactation day 1
(sample HP-Y 'set'). The color scale of the spots is indicated on the
left as is the current data normalization mode (median). Genes with
white circles are named genes and were selected by the data filter. A
scatter plot of this data is shown on the right with genes passing the
data filter indicated as red + and those not passing the filter
(i.e. ESTs, calibration DNA, user's genes) shown as gray + symbols. A
single gene was selected by clicking on it in the array image and has
a yellow circle (grid 1-D) and a corresponding green circle in the
scatter plot. Information on that gene is indicated above the array
and at the top of the scatter plot. MAExplorer can also be used to
view mean data from sets of samples e.g. Day 13 pregnancies
from C57B6 (3 HP-X samples) vs. Day 1 Lactation (4 HP-Y samples) at low or high resolution.
Table of Contents
Overview
Menu summary
Quick start
1. Introduction
1.1 Microarrays and notation used with MAExplorer
1.2 Microarray image quantification
1.2.1
Ratio and Zscore comparison of data from different hybridized samples
1.3 Microarray image and plot display
1.4 Exploratory data analysis - overview
1.4.1
Saving the state of a data-mining session in stand-alone mode
1.4.2
Logging messages and command history
1.5 Quick start - demonstration of MAExplorer
1.6 Tutorials for using MAExplorer
2. MAExplorer menus
2.1 File menu
2.1.1
Databases menu
2.1.2
Exploratory state menu
2.1.3
Groupware facility for sharing user states menu
2.2 Samples menu
2.2.1
Selecting sample HP with chooser or menu sample lists
2.2.2
Swapping selected samples's (Cy3,Cy5) channels in ratio data
dye-swap experiments
2.2.3
Viewing sample HP-X, HP-Y, and HP-E partitions
2.2.4
Defining sample condition 'class' names
2.2.5
Toggling between single HP-X (-Y) samples and HP-X (-Y) sets
2.3 Edit menu
2.3.1
User edited gene list - the 'Edited Gene List' menu
2.3.2
Sets of genes menu
2.3.3
Sets of Sample Conditions menu
2.3.4
Setting user preferences menu
2.4 Analysis
2.4.1 GeneClass menu
2.4.1.1
GeneClass ontology subsets
2.4.1.2
Simulating Gene Class ontologies using Gene Set operations
2.4.2 Normalization menu
2.4.2.1
Intensity background correction
2.4.2.2
Normalization between microarrays to allow comparison
2.4.2.3
Using different normalizations to 'see' different data views
2.4.3 Filter menu
2.4.3.1
Data filtering using multiple gene data filters
2.4.4 Plot menu
2.4.4.1
Show microarray pseudoarray images menu
2.4.4.2
Scatter plots menu
2.4.4.3
Histogram plots menu
2.4.4.4
Expression profile plots menu
2.4.5
Cluster menu
2.4.5.1
Cluster genes with expression profiles similar to current gene
2.4.5.2
Cluster counts of similar filtered genes by expression profiles
2.4.5.3
K-means clustering' gene expression profiles for filtered genes
2.4.5.4
Hierarchical clustering of expression profiles
2.4.6 Report menu
2.4.6.1
Array report menu - hybridized samples global data
2.4.6.2
Gene reports menu
2.4.6.3
Table format menu
2.4.6.4
Table font size menu
2.5 View menu
2.5.1
Logging MAExplorer messages
2.5.2
Logging command history
2.6 Plugins menu
2.7 Help menu
3.
Exploratory Data Analysis - Data Mining
3.1 Analysis objectives
3.1.1
Some experimental design issues of microarray experiments
3.1.2
Design philosophy of MAExplorer methodology
3.1.3
Evolution of MAExplorer from earlier proteomic data mining systems
3.1.4
Concepts used in data mining with MAExplorer
3.2
Steps in an analysis
3.2.1
Definition of expression profile
3.2.2
Clustering Methods
3.2.2.1
Clustering similar genes
3.2.2.2
K-means clustering
3.2.2.3 Hierarchical clustering
3.3
Display gene intensity and identification data measurements
3.4
Selecting subsets of genes using the data Filter
3.5
Selecting subsets of hybridized sample conditions
3.6
Setting threshold values using the state-scroller sliders
3.7
Exporting report and plot data
4. Status and Bugs of MAExplorer
4.1 Known Bugs in MAExplorer
4.1.1 Browser Applet Bugs
4.1.2 Downloading and Installer Bugs
4.1.3 Computation speed and display Bugs
4.1.4 User state and login Status
4.1.5 Data file names Bug
4.1.6 Gene Sets Bugs
4.1.7 Clustering Bugs
4.1.8 Expression profile Bugs
4.1.9 Data conversion problems
4.1.10 Java Plugins bugs
4.2 Revision notes
4.3
Web Browser problems when running MAExplorer as an applet
4.4
Handling fatal error reporting (i.e. DRYROT errors)
Release archive
Acknowedgments
References to related exploratory data analysis methods
R.1 Nucleic Acids Res. paper (PDF)
R.2 Overview (PDF)
R.3 Examples (PDF)
R.4 Using mAdb data with MAExplorer (PDF)
R.5 Introduction to Data Mining with MAExplorer(PDF) or
(PPT)
R.6 Using Cvt2Mae to convert array data for use with MAExplorer.(PDF)
R.7 Statistics in Functional Genomics workshop paper (PDF)
R.8 Software design of the MAExplorer data mining tool
(PDF) or
(PPT)
Newsletters
Appendices
A. Short tutorial for MAExplorer
A.1 Demonstration data
A.2 General instructions
A.3 Self-guided tutorial of MAExplorer - notation and examples
B. Advanced tutorial
C. Use of MAExplorer with user's microarray data
C.1
Creating quantified spot data files from hybridized sample arrays
C.2
Table of samples that can be loaded into MAExplorer
C.3
Quantified spot data file format
C.4
GIPO table database file format
C.5
Configuring MAExplorer for use with other arrays
C.6
Using the Cvt2Mae 'wizard' tool to convert array data for use with
MAExplorer
D.
Use of MAExplorer as a stand-alone application
D.1
Installing MAExplorer as stand-alone application
D.2
Downloading MAExplorer for stand-alone use with other arrays
D.3
Starting MAExplorer by clicking on a .mae file
D.4
The data file format for .mae files
D.5
Using MAExplorer as an Applet on your computer
D.6
List of startup .mae files included in the download installation
E. Design issues
E.1
Internal data structures design to facilitate direct manipulation
E.2
Approaches to data mining: client-centric and server-centric models
E.3
Conversion of microarray data files to MAExplorer format using Cvt2Mae
E.4
Extending MAExplorer functionality using Java Plugins
E.5
Web database server design
Download Installers
Installer information
MAExplorer Plugins
Cvt2Mae wizard
MAExplorer Open Source
Download source
javadocs for source
MPL1.1 Public License
Legal
List of Figures
List of Tables
Glossary of terms used in MAExplorer
Index
Help
desk
MAExplorer - Overview
MAExplorer is a bioinformatics microarray data mining Java application
that may help in the discovery of genes regulated in cancer and other
diseases. MAExplorer is generally run as as a stand-alone application on a
local computer. By running as a local application, it is able to
access your local disk to save the state of your data mining session
as well as plots and reports. Using the previously saved data mining
state, you can continue a data-mining session at a later date after
exiting the program.
- MAExplorer helps perform computer data-mining of multiple samples
hybridized with microarrays. Data mining is the process of attempting
to find relevant patterns of information from large sets of data.
MAExplorer enables the investigator to:
- organize the hybridized sample data by experimental condition,
(including: disease state, dose response, developmental stage,
strain, time course, knock-in/-out, shock treatment, etc.) so an
investigator can design data mining experiments relevant to
those conditions or a subset of conditions from a particular database.
- compare gene expression patterns between sets of
different hybridized samples (denoted HP-X and HP-Y 'sets') for
comparing mean changes between replicate sets of samples. An
ordered expression profile list HP-E of samples is used for
finding similar expression patterns across genes for a sequence of
samples such as from the cell cycle, developmental stage, or
conditions.
- use data mining techniques of graphical direct-manipulation
(which requires the real-time response of local computation),
statistical, clustering and spreadsheet techniques, and
connectivity to other Internet genomic databases to get additional
information on individual genes. The latter leverages the
maintenance resources of other groups to allow transparent access
to that data.
- explore, compare, and record analyses between researchers in
their own group and for sharing with other investigators
(i.e. groupware).
- Spots in microarray images are quantified into tab-delimited
data files using programs such as generated by Axon's
GenePix(TM), Scanalyze, Molecular Dynamic's
ImageQuant-NT(TM), Research Genetics'
Pathways(TM), and other systems. This data is transformed
using the Cvt2Mae wizard
data conversion tool to quantification data files, a print-file (Gene In Plate Order table or GIPO),
a list of DB samples file, and a MAExplorer configuration file. These
may be copied to your local computer file system (in stand-alone
operation) or a MAExplorer-compatible Web database server where they
are loaded on demand by MAExplorer. The file formats schema used by
MAExplorer is discussed in Appendix C). The data
conversion tool Cvt2Mae
(Appendix C.6) helps convert user's data sets to MAExplorer
format.
- Upon starting, MAExplorer uses a ".mae" startup file to
specify the subset of samples to be used from the database, and
initial parameters to use. It then loads a configuration file which
describes additional files including the gene-in-plate-order table
which maps spot position to clone ID and other genomic information,
and a samples database file containing a list of the names of the
quantified spot data files for the hybridized samples being analyzed.
Later, you may request additional sample files or data from the local
file system or Web database server when requested by the user. The
.mae file format is discussed in Appendix
D. Users may save data mining sessions to create new .mae startup
files. These may be used at a later for continuing their sessions in the
future.
- The investigator interacts directly with the system by selecting
entries from menus (Section 2), selecting
data by clicking on spots in the microarray image, selecting points in graphic
plots or cells in spreadsheets, manipulating threshold sliders, or
typing in gene names, clone IDs, GenBank IDs, UniGene IDs, LocusLink
IDs, etc. Data reports may be exported to Excel spreadsheets or used
dynamically to access other genomic Web databases. With the
stand-alone version, you may save the full resolution plots in GIF
files and report tables in tab-delimited text files.
Recommended Hardware
Because data mining is a computationally and graphically intensive
activity, a reasonable level of computation resources are required for
adequate response. The same Java program runs on a variety of
operating systems including Windows 95/98/Me/NT/2000, Macintosh
OS8/9/X, Solaris, Linux, etc. so the choice of computer is not that
critical. We recommend the following hardware:
- A computer with at least 500Mhz CPU speed (Intel). For other CPUs
such as the PowerPC (Macintosh), Sparc (Sun), etc., it should have a
corresponding capability (for more powerful CPU chips, a lower CPU
speed may be fine). For large data sets (order of 100 or more) having
a large number of samples with many spots, a much faster system with
much more memory is desirable.
- At least 128Mbytes of memory. Although it will work with less
memory, we don't recommend it as it is underpowered. For large
data sets, more memory (eg. 256Mb or more) is desirable.
- Adequate disk space for the data sets required. The MAExplorer
distribution itself, including the MGAP demonstration database and a
Java Virtual Machine, is on the order of 24 Mbytes. This Reference
Manual with both low and high resolution figures is on the order of 11
Mbytes.
- It requires at least a 1024x768 pixel resolution 256-color
monitor. However, we find that because of the multiple plots created
during a session, it is much easier to use with a screen resolution of
1280x1024 pixels. It is very difficult to use with an 800x600
resolution system and we don't recommend it.
- The
R extensions are not available with MacOS 8/9. Using the R
extensions requires more memory - at least 256Mbytes with a faster
processor is recommended.
Addition of user defined analysis methods using Java Plugins
We have provided the ability for users to add their own Java Plugin
Extensions to MAExplorer. These extend the capabilities of the core
MAExplorer program to other more sophisticated analysis methods
created by users and allow interaction with specialized genomic
servers. This is described in Appendix E, Section 2.6, and in the MAExplorer Plugins Web page.


{kind=link}
{kind=link}